Les vélos sur le pont de Fremont#
à télécharger
pour exécuter ce code localement sur votre ordi,
commencez par télécharger le zip
lien vers la version originale
Voir la version originale de ce code - par Jake Vanderplas - sur Youtube
https://www.youtube.com/watch?v=_ZEWDGpM-vM&list=PLYCpMb24GpOC704uO9svUrihl-HY1tTJJ
On part des données publiques qui décrivent le trafic des vélos sur le pont de Fremont (à Portland - Oregon)
URL = "https://data.seattle.gov/api/views/65db-xm6k/rows.csv?accessType=DOWNLOAD"
import pandas as pd
# on a déja le fichier en local
local_file = "data/fremont.csv"
pour information, voici le code qu’on a utilisé pour aller chercher la donnée
# ceci nécessite alors
# %pip install requests
from pathlib import Path
if Path(local_file).exists():
print(f"le fichier {local_file} est déjà là")
else:
print(f"allons chercher le fichier {local_file}")
import requests
req = requests.get(URL)
# doit afficher 200
print(req.status_code)
# on sauve tel quel dans le fichier local
with open(local_file, 'w') as writer:
writer.write(req.text)
le fichier data/fremont.csv est déjà là
!head $local_file
Date,Fremont Bridge Total,Fremont Bridge East Sidewalk,Fremont Bridge West Sidewalk
08/01/2022 12:00:00 AM,23,7,16
08/01/2022 01:00:00 AM,12,5,7
08/01/2022 02:00:00 AM,3,0,3
08/01/2022 03:00:00 AM,5,2,3
08/01/2022 04:00:00 AM,10,2,8
08/01/2022 05:00:00 AM,27,5,22
08/01/2022 06:00:00 AM,100,43,57
08/01/2022 07:00:00 AM,219,90,129
08/01/2022 08:00:00 AM,335,143,192
chargement#
%pip install seaborn
Requirement already satisfied: seaborn in /home/docs/checkouts/readthedocs.org/user_builds/flotpython-exos-ds/envs/devel/lib/python3.13/site-packages (0.13.2)
Requirement already satisfied: numpy!=1.24.0,>=1.20 in /home/docs/checkouts/readthedocs.org/user_builds/flotpython-exos-ds/envs/devel/lib/python3.13/site-packages (from seaborn) (2.3.3)
Requirement already satisfied: pandas>=1.2 in /home/docs/checkouts/readthedocs.org/user_builds/flotpython-exos-ds/envs/devel/lib/python3.13/site-packages (from seaborn) (2.3.2)
Requirement already satisfied: matplotlib!=3.6.1,>=3.4 in /home/docs/checkouts/readthedocs.org/user_builds/flotpython-exos-ds/envs/devel/lib/python3.13/site-packages (from seaborn) (3.10.6)
Requirement already satisfied: contourpy>=1.0.1 in /home/docs/checkouts/readthedocs.org/user_builds/flotpython-exos-ds/envs/devel/lib/python3.13/site-packages (from matplotlib!=3.6.1,>=3.4->seaborn) (1.3.3)
Requirement already satisfied: cycler>=0.10 in /home/docs/checkouts/readthedocs.org/user_builds/flotpython-exos-ds/envs/devel/lib/python3.13/site-packages (from matplotlib!=3.6.1,>=3.4->seaborn) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /home/docs/checkouts/readthedocs.org/user_builds/flotpython-exos-ds/envs/devel/lib/python3.13/site-packages (from matplotlib!=3.6.1,>=3.4->seaborn) (4.60.0)
Requirement already satisfied: kiwisolver>=1.3.1 in /home/docs/checkouts/readthedocs.org/user_builds/flotpython-exos-ds/envs/devel/lib/python3.13/site-packages (from matplotlib!=3.6.1,>=3.4->seaborn) (1.4.9)
Requirement already satisfied: packaging>=20.0 in /home/docs/checkouts/readthedocs.org/user_builds/flotpython-exos-ds/envs/devel/lib/python3.13/site-packages (from matplotlib!=3.6.1,>=3.4->seaborn) (25.0)
Requirement already satisfied: pillow>=8 in /home/docs/checkouts/readthedocs.org/user_builds/flotpython-exos-ds/envs/devel/lib/python3.13/site-packages (from matplotlib!=3.6.1,>=3.4->seaborn) (11.3.0)
Requirement already satisfied: pyparsing>=2.3.1 in /home/docs/checkouts/readthedocs.org/user_builds/flotpython-exos-ds/envs/devel/lib/python3.13/site-packages (from matplotlib!=3.6.1,>=3.4->seaborn) (3.2.4)
Requirement already satisfied: python-dateutil>=2.7 in /home/docs/checkouts/readthedocs.org/user_builds/flotpython-exos-ds/envs/devel/lib/python3.13/site-packages (from matplotlib!=3.6.1,>=3.4->seaborn) (2.9.0.post0)
Requirement already satisfied: pytz>=2020.1 in /home/docs/checkouts/readthedocs.org/user_builds/flotpython-exos-ds/envs/devel/lib/python3.13/site-packages (from pandas>=1.2->seaborn) (2025.2)
Requirement already satisfied: tzdata>=2022.7 in /home/docs/checkouts/readthedocs.org/user_builds/flotpython-exos-ds/envs/devel/lib/python3.13/site-packages (from pandas>=1.2->seaborn) (2025.2)
Requirement already satisfied: six>=1.5 in /home/docs/checkouts/readthedocs.org/user_builds/flotpython-exos-ds/envs/devel/lib/python3.13/site-packages (from python-dateutil>=2.7->matplotlib!=3.6.1,>=3.4->seaborn) (1.17.0)
Note: you may need to restart the kernel to use updated packages.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# version naïve
data = pd.read_csv(local_file); data.shape
(175200, 4)
data.head()
| Date | Fremont Bridge Total | Fremont Bridge East Sidewalk | Fremont Bridge West Sidewalk | |
|---|---|---|---|---|
| 0 | 08/01/2022 12:00:00 AM | 23.0 | 7.0 | 16.0 |
| 1 | 08/01/2022 01:00:00 AM | 12.0 | 5.0 | 7.0 |
| 2 | 08/01/2022 02:00:00 AM | 3.0 | 0.0 | 3.0 |
| 3 | 08/01/2022 03:00:00 AM | 5.0 | 2.0 | 3.0 |
| 4 | 08/01/2022 04:00:00 AM | 10.0 | 2.0 | 8.0 |
doublons#
en fait ce qu’il se passe c’est que c’est un peu le bazar ce dataset, et que les données sont principalement présentes en deux exemplaires !
!grep '01/01/2014 12:00:00 AM' $local_file
01/01/2014 12:00:00 AM,23,5,18
01/01/2014 12:00:00 AM,23,5,18
du coup on nettoie
data.drop_duplicates(inplace=True)
data.shape
(87600, 4)
parser les dates#
# intéressant aussi, pour voir notamment les points manquants
data.info();
<class 'pandas.core.frame.DataFrame'>
Index: 87600 entries, 0 to 87599
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 87600 non-null object
1 Fremont Bridge Total 87586 non-null float64
2 Fremont Bridge East Sidewalk 87586 non-null float64
3 Fremont Bridge West Sidewalk 87586 non-null float64
dtypes: float64(3), object(1)
memory usage: 3.3+ MB
# ou tout simplement
data.dtypes
Date object
Fremont Bridge Total float64
Fremont Bridge East Sidewalk float64
Fremont Bridge West Sidewalk float64
dtype: object
bref le point ici c’est que les dates sont des chaines et pas des dates
# la version lente
# avec cette forme, on demanderait à read_csv:
# de mettre la date comme index,
# et de parser les dates
# mais on ne va pas le faire car
# 1. c'est peu sûr
# 2. c'est trop lent
# data = pd.read_csv(local_file, index_col='Date', parse_dates=True); data.head()
# une meilleure idée, pour améliorer ces deux points d'un coup
# est de fournir nous-même le format des dates
data.index = pd.to_datetime(data.Date, format="%m/%d/%Y %I:%M:%S %p")
del data['Date']
data.head()
| Fremont Bridge Total | Fremont Bridge East Sidewalk | Fremont Bridge West Sidewalk | |
|---|---|---|---|
| Date | |||
| 2022-08-01 00:00:00 | 23.0 | 7.0 | 16.0 |
| 2022-08-01 01:00:00 | 12.0 | 5.0 | 7.0 |
| 2022-08-01 02:00:00 | 3.0 | 0.0 | 3.0 |
| 2022-08-01 03:00:00 | 5.0 | 2.0 | 3.0 |
| 2022-08-01 04:00:00 | 10.0 | 2.0 | 8.0 |
renommons les colonnes#
# les noms de colonne ne sont pas pratiques du tout
data.columns = ['Total', 'West', 'East']
données manquantes et extension types#
de manière totalement optionnelle, mais on remarque que les nombres ont été convertis en flottants
et ça c’est parce qu’il y a eu quelques interruptions de service, apparemment, avec le système de récolte de l’information
data[data['Total'].isna()]
| Total | West | East | |
|---|---|---|---|
| Date | |||
| 2013-03-10 02:00:00 | NaN | NaN | NaN |
| 2013-06-14 09:00:00 | NaN | NaN | NaN |
| 2013-06-14 10:00:00 | NaN | NaN | NaN |
| 2014-03-09 02:00:00 | NaN | NaN | NaN |
| 2015-03-08 02:00:00 | NaN | NaN | NaN |
| 2015-04-21 11:00:00 | NaN | NaN | NaN |
| 2015-04-21 12:00:00 | NaN | NaN | NaN |
| 2016-03-13 02:00:00 | NaN | NaN | NaN |
| 2017-03-12 02:00:00 | NaN | NaN | NaN |
| 2018-03-11 02:00:00 | NaN | NaN | NaN |
| 2019-03-10 02:00:00 | NaN | NaN | NaN |
| 2020-03-08 02:00:00 | NaN | NaN | NaN |
| 2021-03-14 02:00:00 | NaN | NaN | NaN |
| 2022-03-13 02:00:00 | NaN | NaN | NaN |
# ou encore si on préfère
data[data.isna().any(axis=1)].shape
(14, 3)
on pourrait nettoyer, mais ici on va choisir d’ignorer ces données manquantes; à la place on va les remettre sous la forme d’entiers
# ceci va nous permettre d'avoir des colonnes d'entiers - avec des nan
data = data.convert_dtypes(convert_integer=True)
data.head()
| Total | West | East | |
|---|---|---|---|
| Date | |||
| 2022-08-01 00:00:00 | 23 | 7 | 16 |
| 2022-08-01 01:00:00 | 12 | 5 | 7 |
| 2022-08-01 02:00:00 | 3 | 0 | 3 |
| 2022-08-01 03:00:00 | 5 | 2 | 3 |
| 2022-08-01 04:00:00 | 10 | 2 | 8 |
# ça ressemble à ceci
data.dtypes
Total Int64
West Int64
East Int64
dtype: object
# on a toujours les n/a, mais ce n'est pas grave
data[data.isna().any(axis=1)].shape
(14, 3)
à quoi ça ressemble#
%matplotlib inline
# no longer working ?
# plt.style.use('seaborn')
sns.set(rc={'figure.figsize': (12, 4)})
#plt.rcParams["figure.figsize"] = (12, 4)
# un premier jet, pas terrible du tout
data[['East', 'West']].plot();
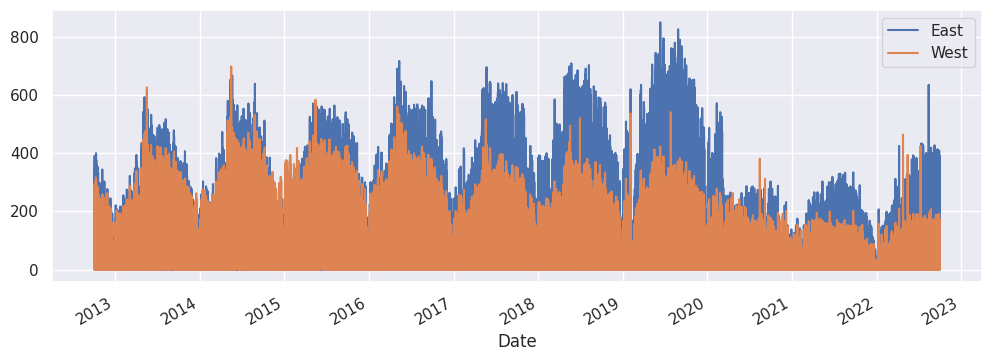
ajustement#
# c'est plus lisible avec seulement un point par semaine
# on pourrait faire la moyenne aussi bien sûr,
# ça donnerait le même dessin mais avec les Y divisés par 7
# le point c'est qu'on a quelques années de plus que sur la vidéo
data.resample('W').sum().plot();
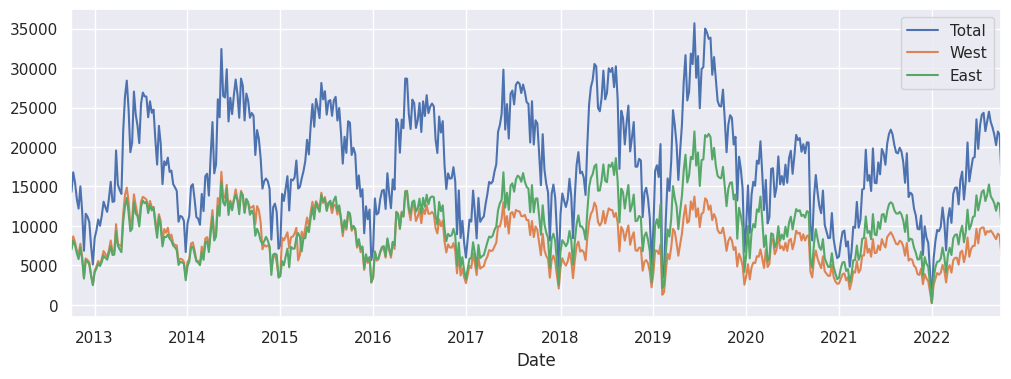
juste pour être en phase (pouvoir vérifier nos résultats par rapport à ceux de la vidéo), on va s’arrêter à la fin de 2017
(un détail à noter aussi, les données de la vidéo ne contenaient pas la colonne ‘total’…)
# c'est facile de couper, la date correpond à l'index de la df
# et grâce au type 'datetime' on peut simplement faire une comparaison
data = data[data.index.year <= 2017]
quiz
ici on s’en sort bien car on coupe au début d’une année
mais comment ferait-on pour couper au 12 Février à 14h32:30 ?
data.tail(3)
| Total | West | East | |
|---|---|---|---|
| Date | |||
| 2017-12-31 21:00:00 | 13 | 3 | 10 |
| 2017-12-31 22:00:00 | 13 | 7 | 6 |
| 2017-12-31 23:00:00 | 16 | 7 | 9 |
data.resample('W').sum().plot();
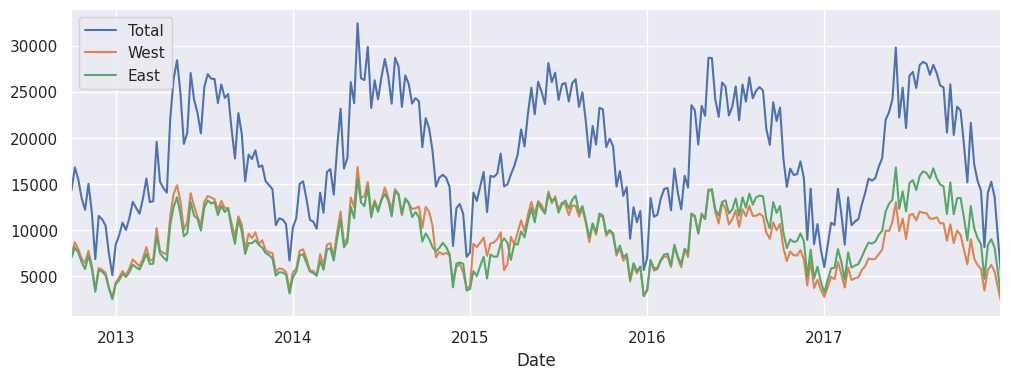
resample() ?#
décortiquons un peu cette histoire de resample()
data.shape
(45984, 3)
# la forme du resample() est de:
data.resample('1W').sum().shape
(274, 3)
# on vérifie que la version resamplée a bien
# 7 * 24 = 168 fois moins d'entrées que la version brute
# puisqu'on a une mesure par heure et qu'on ré-échatillonne sur une semaine
(full, _), (resampled, _) = data.shape, data.resample('1W').sum().shape
full / resampled , 7 * 24
(167.82481751824818, 168)
reprenons#
data.resample('1W').sum().plot();
# la somme sur une fenêtre tournante d'un an
# mais : méfiez-vous de l'échelle des Y
data.resample('1D').sum().rolling(365).sum().plot();
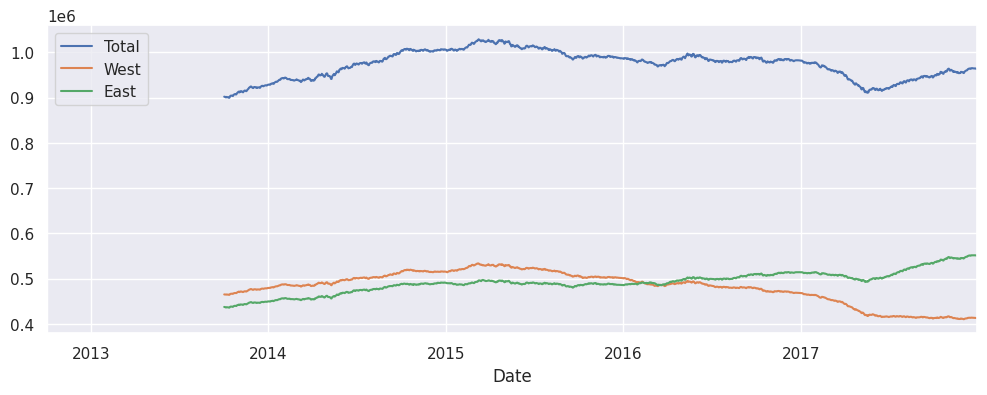
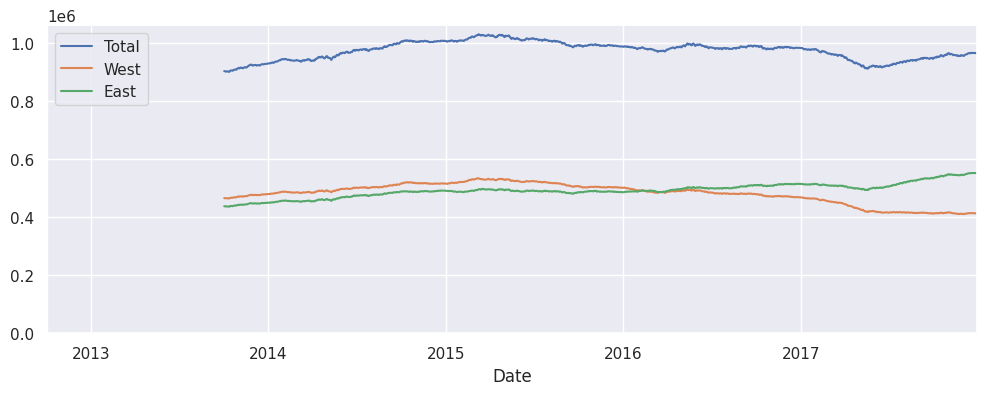
# on fait en sorte que le bas de l'échelle des Y soit bien 0
# pour eviter l'effet de loupe
ax = data.resample('1D').sum().rolling(365).sum().plot()
ax.set_ylim(0, None);
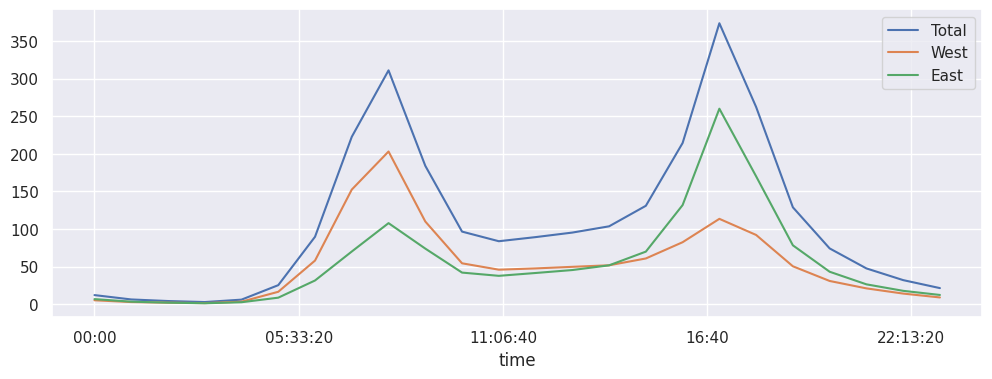
# regardons la tendance des profils journaliers en moyenne
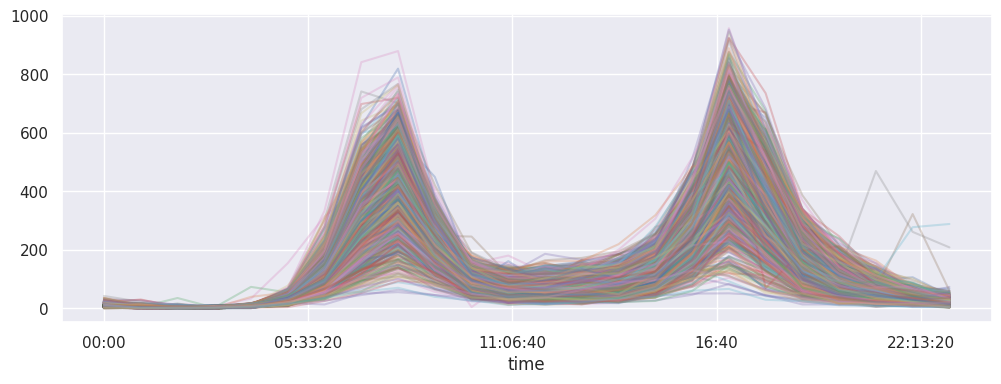
data.groupby(data.index.time).mean().plot();
# mais pour y voir un peu mieux on veut afficher les jours
# individuellement les uns des autres
# on veut donc dessiner autant de courbes que de jours
# et chaque courbe a en X l'heure de la journée et en Y le nombre (total) de passages
# pour ça on calcule une pivot table
# une courbe par jour: les colonnes sont les jours
# en X les heures: les lignes sont les heures
# ça pourrait se faire à coups de groupby/unstack
# mais c'est quand même plus simple comme ceci
pivoted = data.pivot_table('Total', index=data.index.time, columns=data.index.date)
# regardons le coin en haut à gauche
pivoted.iloc[:5, :5]
| 2012-10-03 | 2012-10-04 | 2012-10-05 | 2012-10-06 | 2012-10-07 | |
|---|---|---|---|---|---|
| 00:00:00 | 13.0 | 18.0 | 11.0 | 15.0 | 11.0 |
| 01:00:00 | 10.0 | 3.0 | 8.0 | 15.0 | 17.0 |
| 02:00:00 | 2.0 | 9.0 | 7.0 | 9.0 | 3.0 |
| 03:00:00 | 5.0 | 3.0 | 4.0 | 3.0 | 6.0 |
| 04:00:00 | 7.0 | 8.0 | 9.0 | 5.0 | 3.0 |
# on confirme les dimensions
pivoted.shape
(24, 1916)
# du coup on n'a plus qu'à dessiner
# l'astuce qui tue c'est alpha=0.01 pour éviter les gros patés
pivoted.plot(legend=False, alpha=0.01);
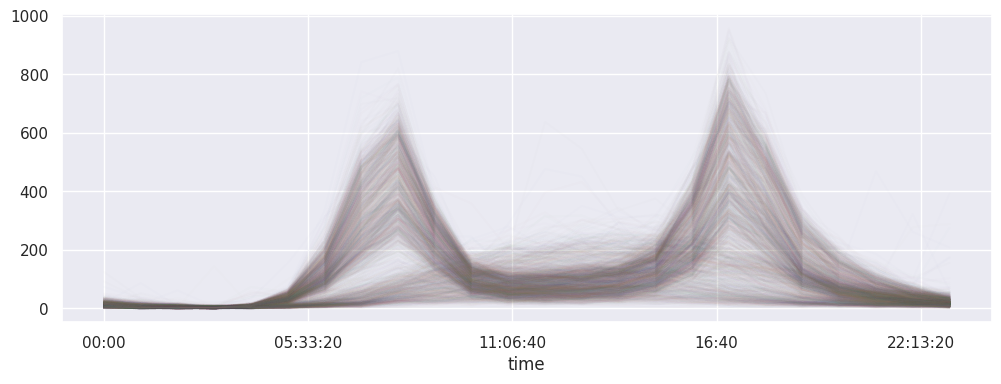
classification#
ici il s’agit de classifier les jours en deux familles, qu’on voit très distinctement sur la figure
on veut faire une ACP sur un tableau qui aurait
les 24 heures en colonnes
les jours en lignes
et donc c’est presque exactement pivoted, sauf que c’est sa transposée !
pivoted.T.shape
(1916, 24)
# ! pip install sklearn
from sklearn.decomposition import PCA
# on transpose, et on remplit les trous avec des 0
pca_input = pivoted.T.fillna(0)
# on utilise le PCA de scikit-learn comme une boite noire
pca_output = PCA(2, svd_solver='full').fit_transform(pca_input)
# on obtient un tableau numpy avec deux colonnes seulement
# car on a demandé les deux premières composantes principales
type(pca_output), pca_output.shape
(numpy.ndarray, (1916, 2))
# on voit effectivement que cet ACP semble bien séparer deux clusters
plt.scatter(pca_output[:, 0], pca_output[:, 1], marker='.', color='green');
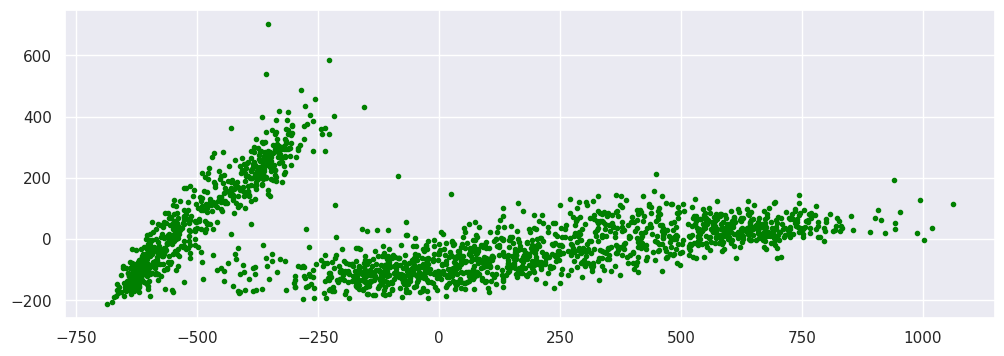
# pour les trouver ces deux clusters, Jake utilise une GaussianMixture
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(2)
# c'est ici que tout se passe
labels = gmm.fit(pca_input).predict(pca_input)
# la sortie est une association jour -> type
labels.shape, labels
((1916,), array([1, 1, 1, ..., 1, 0, 0], shape=(1916,)))
# cette prédiction est bien en phase avec les deux clusters de tout à l'heure
plt.scatter(pca_output[:, 0], pca_output[:, 1], c=labels, cmap='rainbow')
plt.colorbar();
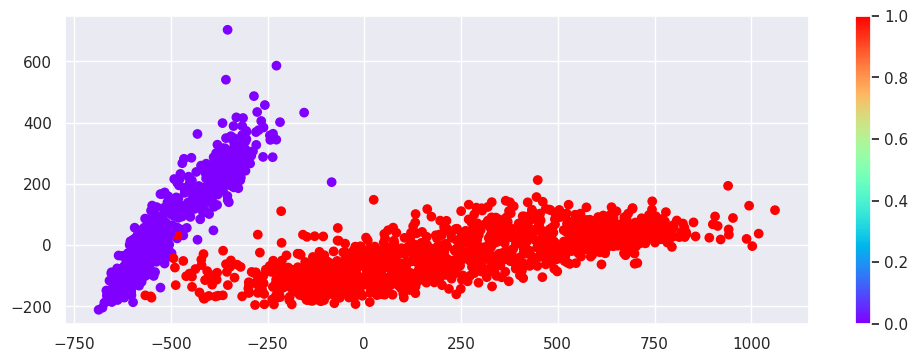
première famille : label==0#
# pour vérifier notre classification on peut redessiner
# les jours classés label==0
# ça correspond donc aux jours de la semaine (à moins que ce soit l'inverse..)
pivoted.loc[:, labels==0].plot(legend=False, alpha=0.01);
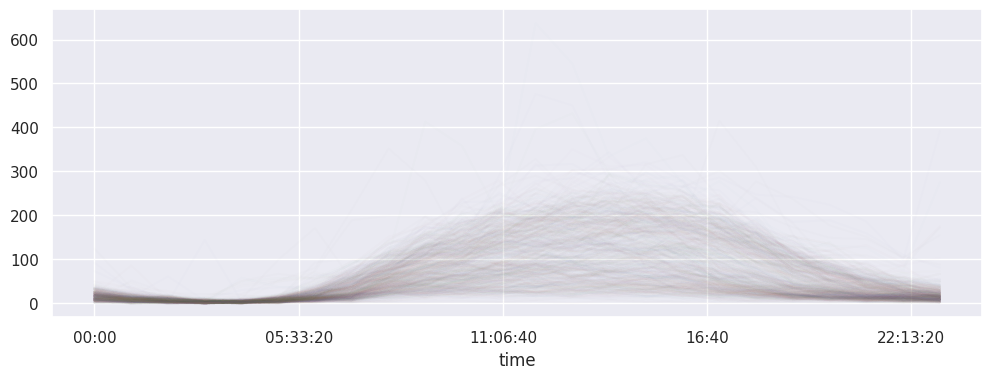
deuxième famille label==1#
# et les jours classés label==1
pivoted.loc[:, labels==1].plot(legend=False, alpha=0.01);
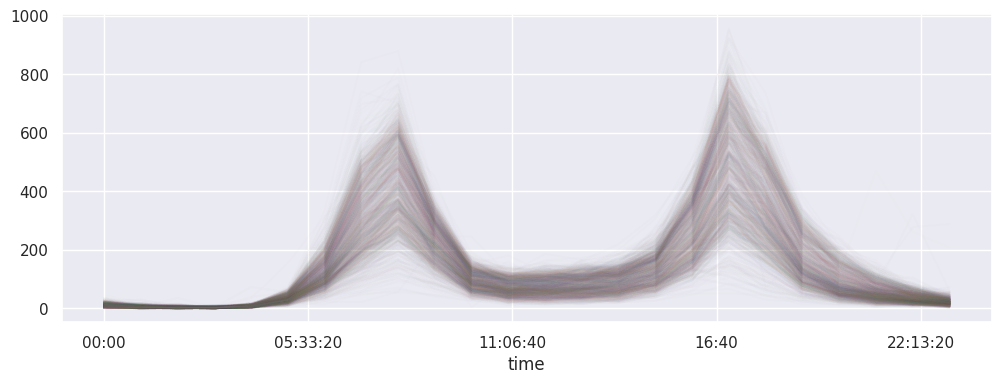
les deux clusters avec le jour de la semaine#
essayons de vérifier que les deux clusters correspondent bien à l’intuition de départ
pour ça on redessine les deux clusters avec une couleur qui indique le jour de la semaine
# notre index horizontal n'est pas de type DatetimeIndex
pivoted.columns
Index([2012-10-03, 2012-10-04, 2012-10-05, 2012-10-06, 2012-10-07, 2012-10-08,
2012-10-09, 2012-10-10, 2012-10-11, 2012-10-12,
...
2017-12-22, 2017-12-23, 2017-12-24, 2017-12-25, 2017-12-26, 2017-12-27,
2017-12-28, 2017-12-29, 2017-12-30, 2017-12-31],
dtype='object', length=1916)
# un index qui contient toutes nos dates et de type DatetimeIndex
dates = pd.DatetimeIndex(pivoted.columns)
# ceci nous calcule un index sur les jours
# mais avec comme valeur 0 pour le lundi, ... et 6 pour le dimanche
dayofweek = pd.DatetimeIndex(pivoted.columns).dayofweek
dayofweek.shape, dayofweek
((1916,),
Index([2, 3, 4, 5, 6, 0, 1, 2, 3, 4,
...
4, 5, 6, 0, 1, 2, 3, 4, 5, 6],
dtype='int32', length=1916))
# qu'on va utiliser pour mettre les jours en couleur
# les jours de weekend sont en orange et rouge
plt.scatter(pca_output[:, 0], pca_output[:, 1], c=dayofweek, cmap='rainbow')
# pour la légende
plt.colorbar();
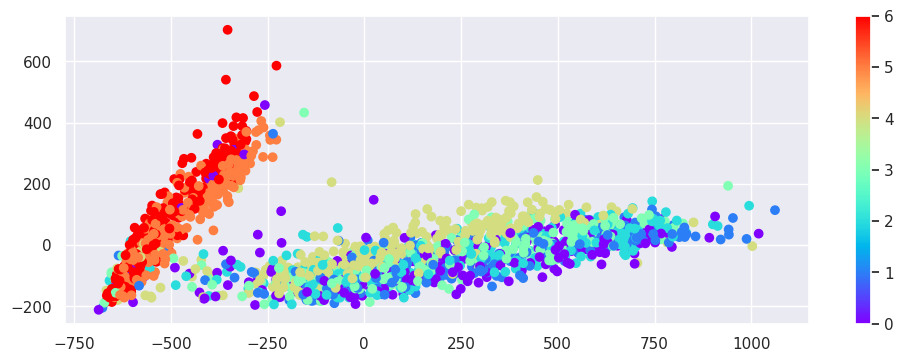
les moutons noirs#
# on remarque dans le cluster rouge-orange
# des jours d'une couleur qui jure
# pour comprendre à quoi ils correspondent
odd_index = (labels == 1) & (dayofweek < 5)
odd_index.shape, odd_index
((1916,),
array([ True, True, True, ..., True, False, False], shape=(1916,)))
# afficher les 48 jours qui sont dans cette catégorie
# comme on peut s'y attendre
# on y retrouve les jours fériés (4 juillet, Noel, ...)
odd_dates = dates[odd_index]
odd_dates, len(odd_dates)
(DatetimeIndex(['2012-10-03', '2012-10-04', '2012-10-05', '2012-10-08',
'2012-10-09', '2012-10-10', '2012-10-11', '2012-10-12',
'2012-10-15', '2012-10-16',
...
'2017-12-14', '2017-12-15', '2017-12-18', '2017-12-19',
'2017-12-20', '2017-12-21', '2017-12-22', '2017-12-27',
'2017-12-28', '2017-12-29'],
dtype='datetime64[ns]', length=1320, freq=None),
1320)
# pour rafficher seulement ces jours-là
pivoted[odd_dates].plot(legend=False, alpha=0.3);