les données covid#
pour travailler localement sur votre PC
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
ce sujet vise à acquérir et mettre en forme les données du COVID pour pouvoir produire facilement des diagrammes comme celui-ci
comme vous le voyez on a choisi:
une liste de pays,
une liste de mesures - ici: deaths & confirmed,
et une plage de temps spécifique

les données de Johns Hopkins#
→
les données sur le corona virus sont publiées par le département Center for Systems Science and Engineering (CSSE), de l’Université Johns Hopkins
sur le dépôt github CSSEGISandData/COVID-19
dans un format brut, détaillé et touffu - un peu trop compliqué pour l’utiliser ici
# le repo github - si vous êtes curieux
official_url = "https://github.com/CSSEGISandData/COVID-19"
autre jeu de données intéressant#
→
un dépôt de seconde main pomber/covid19
consolide les données du CSSE en une unique source
mis à jour quotidiennement
le fichier
timeseries.jsonest en format JSON (JavaScript Object Notation)
# le repo qui va vraiment vous servir, avec le fichier json
json_url = "https://pomber.github.io/covid19/timeseries.json"
le format json ?#
→
vous connaissez sans doute le csv:
un format de données très simple décrivant une table
les éléments séparés par un caractère (
,ou;…)pouvant contenir des identificateurs, des chaînes de caractères et des nombres
json est un format de données bien plus structuré; avec lui on peut sauver les types suivants
nombre,
str(attention, utiliser seulement le"),false,true,nullmais aussi les listes, et les objets (en Python: un dictionnaire, de type
dict)
c’est quoi un dictionnaire ?
pour ceux qui ne sont pas familiers:
les
dictsont les dictionnairesPython
permettant de décrire des objets{attribut1: valeur1, attribut2: valeur2, ...}
par exemple, la liste des animaux avec leur vitesse et leur longévité pourrait être représentée en json par le texte
[
{"name": "snail", "speed": 0.1, "lifespan": 2.0},
{"name": "pig", "speed": 17.5, "lifespan": 8.0},
{"name": "elephant", "speed": 40.0, "lifespan": 70.0},
{"name": "rabbit", "speed": 48.0, "lifespan": 1.5},
{"name": "giraffe", "speed": 52.0, "lifespan": 25.0},
{"name": "coyote", "speed": 69.0, "lifespan": 12.0},
{"name": "horse", "speed": 88.0, "lifespan": 28.0}
]
ou encore sous une autre forme, toujours en json
{"speed":
{"snail":0.1,
"pig":17.5,
"elephant":40.0,
"rabbit":48.0,
"giraffe":52.0,
"coyote":69.0,
"horse":88.0},
"lifespan":
{"snail":2.0,
"pig":8.0,
"elephant":70.0,
"rabbit":1.5,
"giraffe":25.0,
"coyote":12.0,
"horse":28.0}
}
format json pour le covid#
→
revenons au covid
le fichier https://pomber.github.io/covid19/timeseries.json contient un objet dict dont
les clés sont les pays du monde
chaque valeur est une liste de
dict
chacun décrivant une mesure de covid avec les 4 clés:date,confirmed,deathsetrecovered
{
"Afghanistan": [
{
"date": "2020-1-22",
"confirmed": 0,
"deaths": 0,
"recovered": 0
},
{
"date": "2020-1-23",
"confirmed": 0,
"deaths": 0,
"recovered": 0
},
{
"date": "2020-1-24",
"confirmed": 0,
"deaths": 0,
"recovered": 0
}, ...
acquisition des données json#
avec pd.read_json#
→
on ne va pas faire comme ça ici, mais sachez que c’est la méthode la plus rapide (à écrire):
data = pd.read_json(json_url)
par contre ça peut être franchement long, surtout si votre connexion réseau n’est pas au top
c’est pourquoi on va voir aussi une autre méthode - que vous pouvez sauter si vous êtes pressés de voir le traitement des données per se
caching avec requests#
en utilisant la librairie requests on peut implémenter un caching pour nos données
caching ?
dans le cas présent le terme caching suggère que l’on sauverait le fichier sur disque après l’avoir download depuis Internet; de cette façon on n’attend qu’une seule fois la durée du download
par contre, c’est bien d’être malin et de, par exemple, considérer que les fichiers qui ont plus de 1 jour ne sont plus valides et qu’il faut retourner les chercher; mais bon, let’s keep it simple, on ne va pas aller jusque là…
→ requests.get pas à pas
le module requests permet de récupérer des fichiers sur Internet
utiliser cette approche permet de toujours avoir des données récentes
mais demande une bonne connexion à Internet
sinon allez à la slide (l’encadré) suivante qui utilise des données figées
requests n’est pas dans la librairie standard
il faut donc l’installer comme d’habitude avec pip
(on fait comment déjà ?)
une fois que c’est fait on peut l’importer
import requests
avec la fonction requests.get on envoie la requête d’une URL
et on reçoit une réponse
attention la requête suivante (requests.get) demande une bonne connexion
ou beaucoup de patience…
json_url = "https://pomber.github.io/covid19/timeseries.json"
response = requests.get(json_url)
on peut vérifier que l’échange s’est bien passé
response.ok
-> True
la méthode json() sur l’objet Response décode le format JSON
et renvoie les données prêtes pour des traitements en Python
by_country = response.json()
on voit bien une structure Python de dict et de list
correspondant au contenu du fichier json vu ci-dessus
by_country
-> {'Afghanistan': [
{'date': '2020-1-22', 'confirmed': 0, 'deaths': 0,'recovered': 0},
{'date': '2020-1-23', 'confirmed': 0, 'deaths': 0, 'recovered': 0},
{'date': '2020-1-24', 'confirmed': 0, 'deaths': 0, 'recovered': 0},
...
si votre connexion ne vous permet pas la requête
voir la prochaine cellule de cours
# pensez à bien installer le module requests
import requests
json_url = "https://pomber.github.io/covid19/timeseries.json"
by_country = None
# mettez cette variable à True si vous avez une bonne connexion
good_connection = False
#good_connection = True
# le code UNIQUEMENT SI VOUS AVEZ UNE BONNE CONNEXION INTERNET
if good_connection:
response = requests.get(json_url)
print(response.ok)
by_country = response.json()
print(type(by_country))
else:
print('pas bonne connexion - pas grave...')
pas bonne connexion - pas grave...
chargement avec la lib json#
→
si l’accès Internet n’est pas possible, sachez que nous exposons une copie des données
faite il y a quelque temps, dans le fichier data/covid-frozen.json
le module json de la librairie standard permet de lire des fichiers en format JSON;
on l’importe comme d’habitude avec
import json
après avoir ouvert un fichier en lecture,
la fonction json.load lit le contenu dans un objet Python
json_file = 'data/covid-frozen.json'
with open(json_file) as f:
by_country = json.load(f)
et on obtient une structure Python de dict et de list
by_country
-> {'Afghanistan': [
{'date': '2020-1-22', 'confirmed': 0, 'deaths': 0, 'recovered': 0},
{'date': '2020-1-23', 'confirmed': 0, 'deaths': 0, 'recovered': 0},
{'date': '2020-1-24', 'confirmed': 0, 'deaths': 0, 'recovered': 0},
...
# le code
if by_country is not None:
print('on utilise les données déjà chargées')
else:
import json
json_file = 'data/covid-frozen.json'
with open(json_file) as f:
by_country = json.load(f)
print(type(by_country))
<class 'dict'>
# regardons un peu la première clé de ce dictionnaire
# les 4 premières clés
list(by_country.keys())[:4]
['Afghanistan', 'Albania', 'Algeria', 'Andorra']
une dataframe globale#
qui consolide les données covid monde
exercice (version avancé)#
→
il s’agit de construire une unique dataframe contenant toutes les données covid monde
à partir de l’objet python by_country
vous devez obtenir quelque chose comme cela
date confirmed deaths recovered country
0 2020-1-22 0 0 0 Afghanistan
1 2020-1-23 0 0 0 Afghanistan
2 2020-1-24 0 0 0 Afghanistan
3 2020-1-25 0 0 0 Afghanistan
4 2020-1-26 0 0 0 Afghanistan
.. ... ... ... ... ...
??? 2021-8-29 124437 4401 0 Zimbabwe
??? 2021-8-30 124581 4416 0 Zimbabwe
??? 2021-8-31 124773 4419 0 Zimbabwe
??? 2021-9-1 124960 4438 0 Zimbabwe
??? 2021-9-2 125118 4449 0 Zimbabwe
[115050 rows x 5 columns]
attention
les
???peuvent être différents suivant ce que vous faites115050dépend de la date à laquelle le fichier a été récupéré
(et de combien de données étaient alors disponibles)
indications
les élèves avancés peuvent travailler sans indications supplémentaires
pour les autres élèves, on vous propose une méthode pas-à-pas
# votre code
# rangez votre résultat dans la variable global_df
# global_df = ...
exercice (méthode pas-à-pas)#
→
exercice (méthode pas-à-pas) de construction de la dataframe globale
nous allons commencer par créer les dataframes de 2 pays 'France' et 'Italy'
puis les concaténer en une unique dataframe globale
et ensuite généraliser à tous les pays
rappel l’objet Python by_country est un dict dont:
les clés
keys()sont les noms des paysles valeurs
values()sont des séries temporelles (list) d’observations sur le covidchaque observation est un objet exprimé sous la forme d’un
dict
avec 4 mesures indiquées par les attributs'date','confirmed','deaths'et'recovered'
en2021-8-31auZimbabweon a124773cas confirmés,4419morts et0guéris
exo
prenez la clé
'France'
construisez la dataframe à partie de la valeur de cette clé
(la liste des enregistrements temporels de cas de covid)
# votre code
exo
quelles sont les colonnes de cette dataframe ?
combien y-a-t-il d’entrées (de mesures différentes)
# votre code
exo
vous remarquez que cette dataframe ne contient plus l’information sur le pays
ajoutez à cette dataframe une colonne de nom'country'contenant'France'à chaque ligne
# votre code
exo
faites de même avec la clé
'Italy'
et utilisez la fonctionpandas.concatpour concaténer les deux dataframes
# votre code
exo
généralisez et construisez une dataframe avec tous les pays
vous aurez sans doute besoin d’utiliser unforpython
# votre code
index de la dataframe globale#
les index ne sont pas forcément uniques#
si vous avez appelé pd.concat() sans paramètre particulier, vous pouvez sans doute observer ceci:
# si on essaie d'accéder à la ligne d'index 0
# on remarque qu'en fait on obtient .. plein de lignes
global_df.loc[0]
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[15], line 3
1 # si on essaie d'accéder à la ligne d'index 0
2 # on remarque qu'en fait on obtient .. plein de lignes
----> 3 global_df.loc[0]
NameError: name 'global_df' is not defined
→ les index ne sont pas toujours uniques
ce qui s’est passé c’est que :
chacune de nos dataframe par pays a été construite à partir d’un index séquentiel
i.e. un RangeIndex qui commence à chaque fois à 0
et lors du concat on a conservé ces valeurs
ce qui crée une multitude de lignes indexées par 0 (un par pays)
c’est un trait de pandas
contrairement aux dictionnaires Python - où une clé est forcément unique
il est possible de dupliquer plusieurs entrées dans les index
ligne ou colonne - d’une dataframe
même si ça n’est en général pas souhaitable
c’est souvent commode de pouvoir le faire
pendant la phase de construction / mise au point de la dataframe
quitte à adopter par la suite un index plus approprié
(comme on va le faire bientôt)
les dates en pandas#
→
si les valeurs des dates sont de simples str - chaînes de caractères
vous ne pourrez pas leur appliquer de fonctionnalités spécifiques aux dates
la fonction pandas.to_datetime permet de transformer
une chaîne de caratères contenant une date en un objet de type date
d = pd.to_datetime('2020-12-22')
sur lequel vous pouvez appliquer des fonctions spécifiques aux dates
d.year # 2020
d.month # 12
d.day # 22
# le code
d = pd.to_datetime('2020-12-22')
print(d.year, # 2020
d.month, # 12
d.day) # 22
2020 12 22
les formats de dates en pandas#
→
sans indications précises, pandas a inféré le format de la date
ainsi '2020-1-2' sera-t-il compris comme le 2 janvier, et non le 1er février
il est beaucoup plus sûr de passer à pandas.to_datetime le format de vos dates
en utilisant '%Y' pour l’année, %m pour le mois et '%d' pour le jour
on exprime le format des dates dans une chaîne de caractères
'2020-1-2' avec le format '%Y-%m-%d' donnera le 2 janvier 2020
'2020-1-2' avec le format '%Y-%d-%m' donnera le 1 février 2020
pd.to_datetime('2020-1-2', format='%Y-%d-%m').day
-> 1
# sans indication ça peut être ambigu
pd.to_datetime('2020-1-2').day
2
# c'est parfois nécessaire de bien préciser le format
pd.to_datetime('2020-1-2', format='%Y-%d-%m').day
1
# mais sinon c'est très flexible
pd.to_datetime('2021'), pd.to_datetime('aug 2021'),
(Timestamp('2021-01-01 00:00:00'), Timestamp('2021-08-01 00:00:00'))
# .. très flexible
pd.to_datetime('15 july 2021'), pd.to_datetime('15 july 2021 08:00')
(Timestamp('2021-07-15 00:00:00'), Timestamp('2021-07-15 08:00:00'))
convertissons nos dates#
reprenons à partir de la dataframe globale
exo
quel est le type des colonnes ?
# votre code
exo
que pensez-vous du type de la
'date'?
pensez-vous que ce soit adapté pour trier ?
même question pour calculer la durée entre 2 événements ?
comment pourrait-on s’y prendre pour améliorer ça ?
# votre code
exo
regardez la fonction
pandas.to_datetime
sachant que l’année s’écrit%Y, le mois%met le jour%d
écrivez le format qui décrirait une date comme'2020-1-22'
# votre code
exo
créez une nouvelle
Seriesdéduite de la colonnedate
et qui utilise un type plus adapté aux calculs sur les dates quel est le type de la nouvelle colonne ?
# votre code
exo
remplacez dans la dataframe globale la colonne
datepar la précédente
(le mieux est sans doute de conserver le même nom, mais ce n’est pas indispensable)
# votre code
un index plus idoine#
à présent on va pouvoir choisir un index un peu plus adapté à nos données
exo
nous avons vu la notion de MultiIndex
quel serait d’aprés vous un bon choix pour indexer la dataframe globale ?
# votre réponse
exo
voyez-vous un moyen d’utiliser
pivot_table()pour construire une nouvelle
dataframe qui contienne essentiellement les mêmes informations
mais avec un multi-index qui soit pertinent dans le contexte
variante on peut aussi utiliserset_index()
pour aboutir au même résultat
rangez votre résultat dans une variable clean_df
# votre code
accéder via un MultiIndex#
exo
extrayez de la dataframe la série des 3 mesures
faites en France le 1er Janvier 2021
# votre code
exo
(avancé - pas vu en cours)
essayez de trouver/deviner comment extraire de cette dataframe toutes les données relatives à la France
# votre code
exo
même question pour la France et l’Italie
# votre code
un exemple de slicing (très) avancé#
→
pour illustrer la puissance de pandas, et la pertinence de notre choix d’index
voyons comment utiliser du slicing (très très avancé)
pour extraire cette fois les données relatives à
deux pays au hasard - disons
FranceetItalyà la période 1er Juillet - 15 Août 2021 inclus
pour ça on va tirer profit de la structure de l’index
et aussi de la puissance du type datetime64
on va fabriquer :
countries: une liste de pays - c’est faciletime_slice: un slice sur le temps
qui en temps normal pourrait s’écrire'july 2021' : '15 august 2021'
(bornes inclusives puisque.loc[])un slice sur les colonnes
mais au fait on les veut toutes, on peut utiliser:
l’idée serait ensuite d’écrire simplement
clean_df.loc [ (countries, time_slice), :]
tout ça fonctionne presque très bien,
sauf pour la création de time_slice qui, pour de sombres raisons de syntaxe,
ne peut pas se faire ici avec la notation start:stop
(parce que pas dans des [])
et du coup on utilise la fonction builtin slice() pour créer time_slice
# ce qui nous donne le code suivant
# plutôt subtil, mais vraiment puissant
### pour slicer sur les deux composantes de l'index
# NB: si on voulait tous les pays on pourrait faire
# countries = slice(None)
# qui est équivalent à utiliser ::
# sauf qu'à nouveau ce n'est pas possible syntaxiquement ici
countries = ['France', 'Italy']
time_slice = slice('july 2021', '15 aug 2021')
clean_df.loc[
# les lignes: c'est un 2-index donc on peut passer 2 slices
(countries, time_slice),
# les colonnes: on les veut toutes
:]
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[31], line 13
10 countries = ['France', 'Italy']
11 time_slice = slice('july 2021', '15 aug 2021')
---> 13 clean_df.loc[
14 # les lignes: c'est un 2-index donc on peut passer 2 slices
15 (countries, time_slice),
16 # les colonnes: on les veut toutes
17 :]
NameError: name 'clean_df' is not defined
dessinons#
plot d’une dataframe#
→
plutôt que d’utiliser directement la mécanique de matplotlib.pyplot (tendance à être fastidieux)
il est préférable d’utiliser les méthodes comme plot() mais directement sur la dataframe
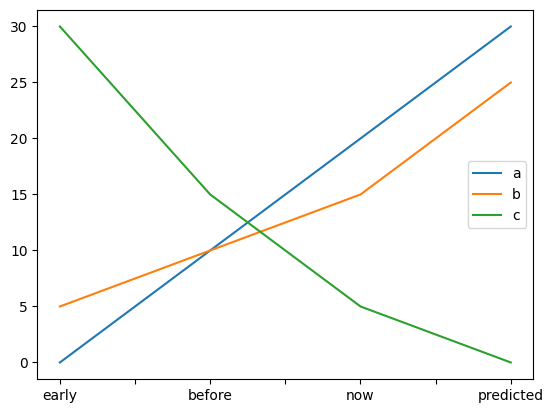
la logique de df.plot() est de dessiner autant de courbes que de colonnes
et de plus pandas se charge de tous les labels! bref c’est recommandé, car plus rapide
# illustration
# 3 colonnes donc 3 courbes
# 4 lignes donc 4 points sur chaque courbe
df = pd.DataFrame(
{'a': [0, 10, 20, 30], 'b': [5, 10, 15, 25], 'c': [30, 15, 5, 0]},
index = ['early', 'before', 'now', 'predicted'],
)
df
| a | b | c | |
|---|---|---|---|
| early | 0 | 5 | 30 |
| before | 10 | 10 | 15 |
| now | 20 | 15 | 5 |
| predicted | 30 | 25 | 0 |
# remarquez que pour toutes les courbes,
# c'est toujours l'index qui sert d'abscisse
df.plot();
sur un pays#
→
du coup on a souvent seulement besoin de mettre en forme les données pour
qu’elles puissent être directement plottées par cette logique simple
imaginons que dans notre cas on veuille comparer sur un graphique l’évolution de
2 mesures :
deaths,confirmedentre 3 pays:
France,ItalyetGermany
il nous faut donc construire une dataframe qui a:
six colonnes - le produit cartésien des 2 mesures et 3 pays
et autant de lignes que de dates - indexé par les dates
mais avant de réfléchir à comment faire ça, commençons par le cas simple d’un seul pays, au moins pour valider l’idée générale
exo
affichez sur un graphique les 3 mesures pour la France au cours du temps
# votre code
exo
idem avec seulement 2 mesures
deathsetconfirmed
# votre code
plusieurs pays#
il nous reste maintenant à traiter le cas de plusieurs pays
exo
extrayez les données pour les 2 mesures et les 3 pays (appelons là
df3)
# votre code
exo
essayez de plotter la dataframe (je vous signale le paramètre
rot=45
qu’on peut passer àdf.plot()pour améliorer la lisibilité)
qu’est ce qui ne va pas malgré cela ?
# votre code
mise en forme des données#
→
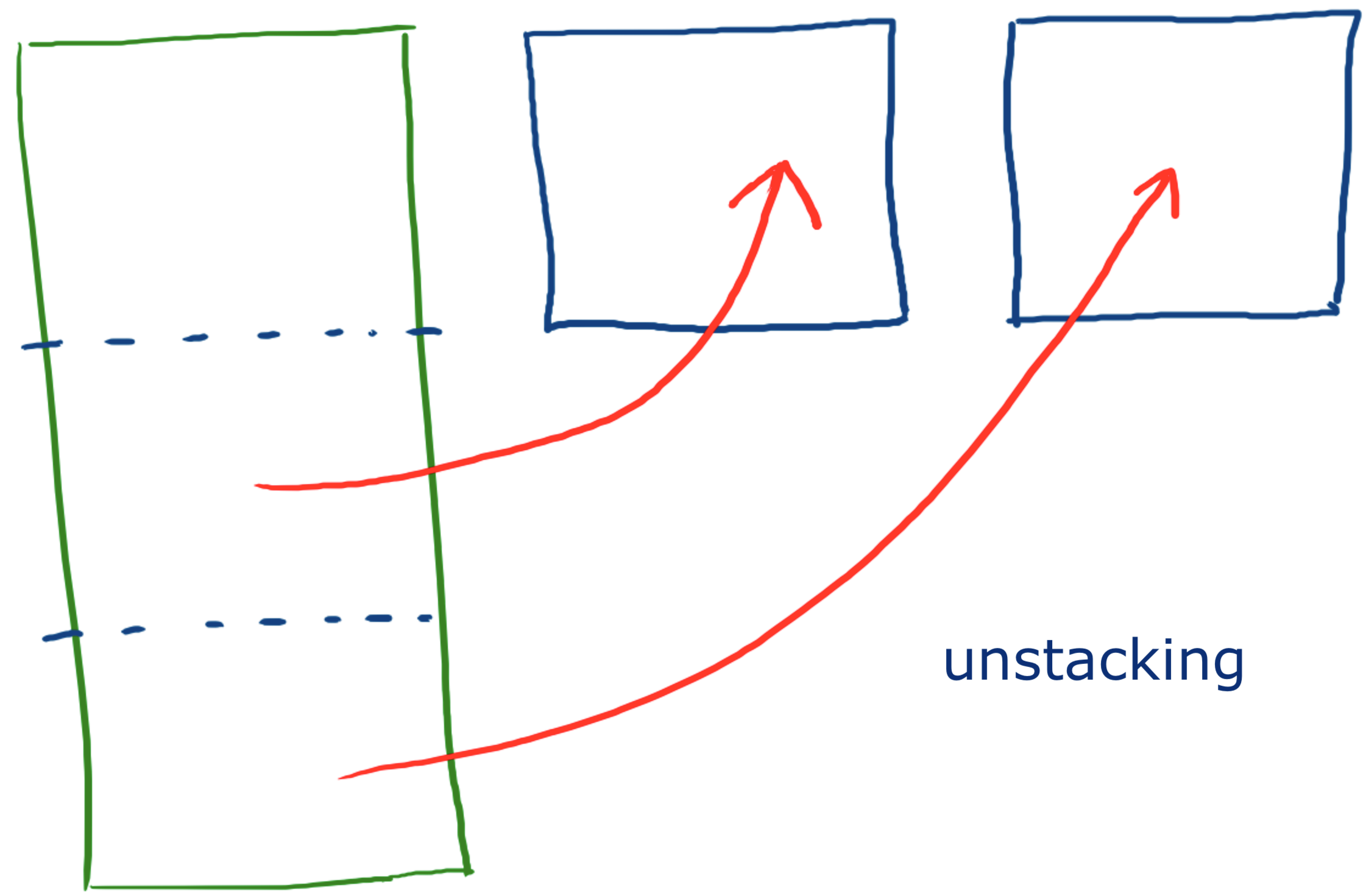
quelle est la forme de df3 ?
à ce stade vous devriez avoir 2 colonnes,
et en gros 3 fois plus de lignes que dans un pays
alors qu’on avait dit qu’on voulait 6 colonnes, et autant de lignes que dans un pays (autant que de jours de mesure)
pour obtenir cette forme (qui bien sûr contient toujours autant de données)
on veut faire un découpage qui ressemble à ceci
df.unstack()#
→
c’est justement le propos de la méthode unstack() sur la dataframe, qui fonctionne
en déplaçant un niveau d’index de l’index des lignes vers l’index des colonnes
dans notre cas précis nous avons
. en lignes un multi-index à deux niveaux country et date
. et en colonnes un index simple (un niveau) de 2 colonnes
et nous pourrions obtenir ce qu’on cherche si on pouvait
en quelque sorte “faire passer” le niveau d’index country
de la direction des lignes à celle des colonnes
comme le niveau d’index country est le premier
donc d’indice 0, on va appeller
df3.unstack(0)
et vous pouvez constater que nous avons à présent
. en lignes un seul niveau d’index - les dates
. en colonnes deux niveaux, les 2 mesures x les 3 pays
# le code du unstack
# df6 = df3.unstack(0)
# df6
ne reste qu’à plotter#
# que du coup il n'y a plus qu'à plotter
#
# à vous
bonus#
→
les rapides peuvent écrire une fonction extract() qui prend en paramètres
les pays concernés
les mesures concernées
et en option pour les plus forts, les dates de début et de fin
et qui retourne une dataframe prête à être affichée comme on l’a fait plus haut