pivot / unstack / groupby#
les pneus#
Vous vous souvenez peut-être que dans les slides on avait construit ceci :
# un code qui crée "à la main" les MultiIndex
# à des fins d'illustration seulement
import pandas as pd
import numpy as np
# index for years and visits
index = pd.MultiIndex.from_product(
[[2013, 2014], [3, 1, 2]],
names=['year', 'visit'])
# columns for clients and tyre pressure
columns = pd.MultiIndex.from_product(
[['Bob', 'Sue'], ['Front', 'Rear']],
names=['client', 'tyre pressure'])
# mock some data
data = 2 + np.random.rand(6, 4)
# create the DataFrame
mechanics_data = pd.DataFrame(data, index=index, columns=columns)
mechanics_data
| client | Bob | Sue | |||
|---|---|---|---|---|---|
| tyre pressure | Front | Rear | Front | Rear | |
| year | visit | ||||
| 2013 | 3 | 2.801388 | 2.137685 | 2.199584 | 2.734917 |
| 1 | 2.548167 | 2.342215 | 2.584093 | 2.131845 | |
| 2 | 2.619265 | 2.857472 | 2.187739 | 2.092210 | |
| 2014 | 3 | 2.690248 | 2.387034 | 2.442620 | 2.918765 |
| 1 | 2.269743 | 2.000530 | 2.138008 | 2.463597 | |
| 2 | 2.866306 | 2.166310 | 2.761579 | 2.792864 | |
générons les données#
dans ce premier code nous avons créé les données directement dans la bonne forme
mais en pratique ce qu’on fournit en général c’est plutôt une table qui ressemble à ceci
# voici comment on pourrait produire une table
# qui serait plus conforme à la réalité
from itertools import product
names = ['Bob', 'Sue']
years = list(range(2013, 2015))
visits = list(range(1, 4))
tyres = ['Front', 'Rear']
# une compréhension de liste
data = [
# qui contient un dictionnaire par ligne
dict(name=name, year=year, visit=visit, tyre=tyre,
# ici on évite le coté "random" en incrémentant
# un peu à chaque pas; la pression est entre 2 et 3
pressure=2+index/25)
#
for index, (name, year, visit, tyre) in
# product pour parcourir le produit cartésien
# sur les 4 dimensions
enumerate(product(names, years, visits, tyres))
]
df = pd.DataFrame(data)
df
| name | year | visit | tyre | pressure | |
|---|---|---|---|---|---|
| 0 | Bob | 2013 | 1 | Front | 2.00 |
| 1 | Bob | 2013 | 1 | Rear | 2.04 |
| 2 | Bob | 2013 | 2 | Front | 2.08 |
| 3 | Bob | 2013 | 2 | Rear | 2.12 |
| 4 | Bob | 2013 | 3 | Front | 2.16 |
| 5 | Bob | 2013 | 3 | Rear | 2.20 |
| 6 | Bob | 2014 | 1 | Front | 2.24 |
| 7 | Bob | 2014 | 1 | Rear | 2.28 |
| 8 | Bob | 2014 | 2 | Front | 2.32 |
| 9 | Bob | 2014 | 2 | Rear | 2.36 |
| 10 | Bob | 2014 | 3 | Front | 2.40 |
| 11 | Bob | 2014 | 3 | Rear | 2.44 |
| 12 | Sue | 2013 | 1 | Front | 2.48 |
| 13 | Sue | 2013 | 1 | Rear | 2.52 |
| 14 | Sue | 2013 | 2 | Front | 2.56 |
| 15 | Sue | 2013 | 2 | Rear | 2.60 |
| 16 | Sue | 2013 | 3 | Front | 2.64 |
| 17 | Sue | 2013 | 3 | Rear | 2.68 |
| 18 | Sue | 2014 | 1 | Front | 2.72 |
| 19 | Sue | 2014 | 1 | Rear | 2.76 |
| 20 | Sue | 2014 | 2 | Front | 2.80 |
| 21 | Sue | 2014 | 2 | Rear | 2.84 |
| 22 | Sue | 2014 | 3 | Front | 2.88 |
| 23 | Sue | 2014 | 3 | Rear | 2.92 |
pivot_table#
typiquement la table du début, on l’aurait créée à partir des données brutes comme ceci
pivot = df.pivot_table(
values='pressure',
index=['year', 'visit'],
columns=['name', 'tyre'])
pivot
| name | Bob | Sue | |||
|---|---|---|---|---|---|
| tyre | Front | Rear | Front | Rear | |
| year | visit | ||||
| 2013 | 1 | 2.00 | 2.04 | 2.48 | 2.52 |
| 2 | 2.08 | 2.12 | 2.56 | 2.60 | |
| 3 | 2.16 | 2.20 | 2.64 | 2.68 | |
| 2014 | 1 | 2.24 | 2.28 | 2.72 | 2.76 |
| 2 | 2.32 | 2.36 | 2.80 | 2.84 | |
| 3 | 2.40 | 2.44 | 2.88 | 2.92 | |
stack/unstack#
unstack()#
unstack() va faire migrer un étage de l’index des colonnes (ici on a deux niveaux year et visit) vers l’espace des colonnes
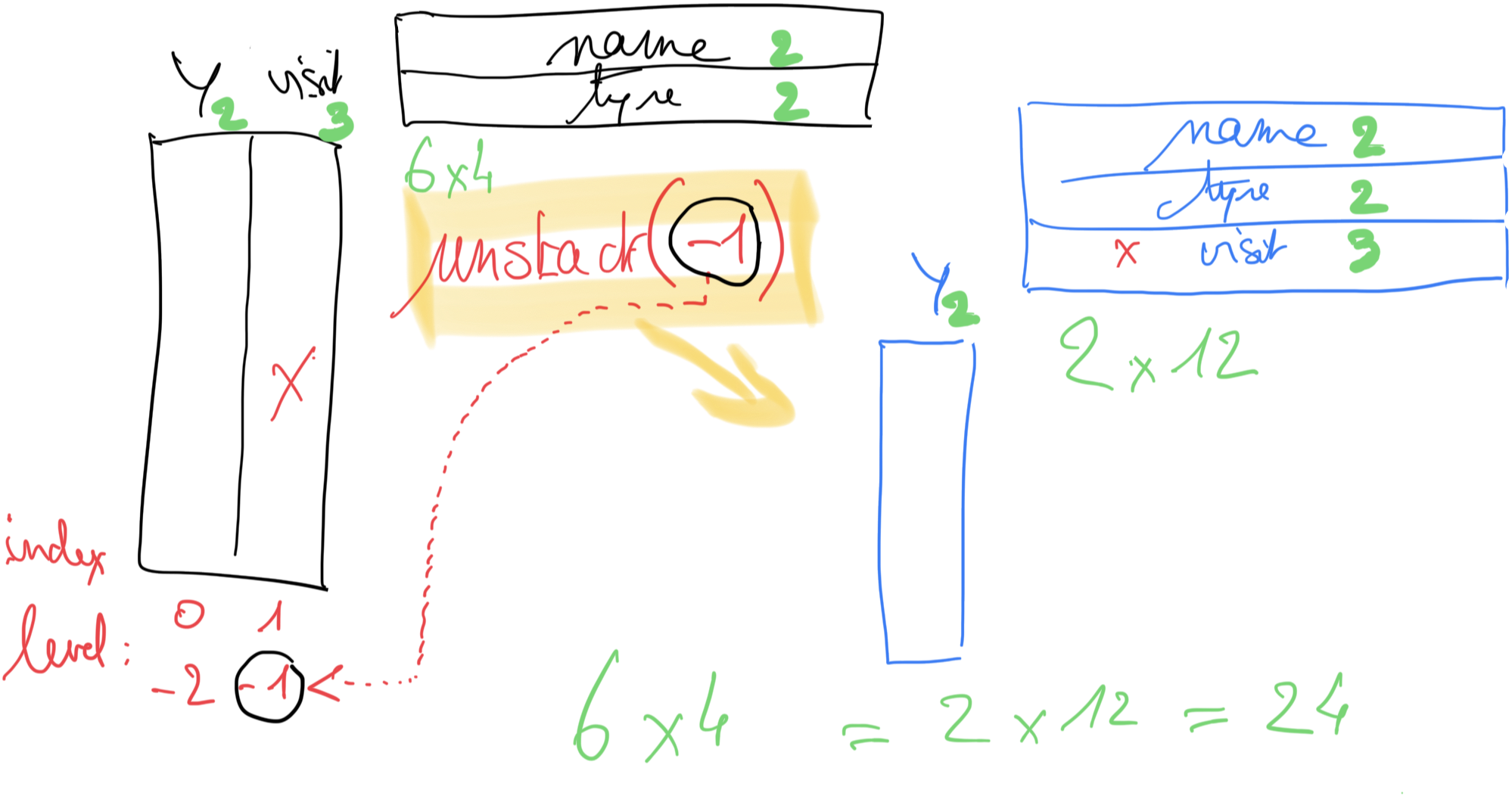
# unstack : on part de la dimension des lignes
# et dans cette dimension notre multi-index contient
# 0: year
# 1: visit (donc aussi -1 car le dernier)
unstacked = pivot.unstack(level=-1)
unstacked
| name | Bob | Sue | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| tyre | Front | Rear | Front | Rear | ||||||||
| visit | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 |
| year | ||||||||||||
| 2013 | 2.00 | 2.08 | 2.16 | 2.04 | 2.12 | 2.20 | 2.48 | 2.56 | 2.64 | 2.52 | 2.60 | 2.68 |
| 2014 | 2.24 | 2.32 | 2.40 | 2.28 | 2.36 | 2.44 | 2.72 | 2.80 | 2.88 | 2.76 | 2.84 | 2.92 |
stack()#
toujours à partir de la forme carrée 2x2 issue du pivot, dans l’autre sens, stack() va faire…
# ici stack part des colonnes vers les index
# donc les niveaux sont
# 0: name
# 1: tyre
# remarquez que je peux aussi bien utiliser le nom
# et que c'est sans doute préférable
stacked = pivot.stack(level='tyre')
stacked
/tmp/ipykernel_1458/1437667771.py:9: FutureWarning: The previous implementation of stack is deprecated and will be removed in a future version of pandas. See the What's New notes for pandas 2.1.0 for details. Specify future_stack=True to adopt the new implementation and silence this warning.
stacked = pivot.stack(level='tyre')
| name | Bob | Sue | ||
|---|---|---|---|---|
| year | visit | tyre | ||
| 2013 | 1 | Front | 2.00 | 2.48 |
| Rear | 2.04 | 2.52 | ||
| 2 | Front | 2.08 | 2.56 | |
| Rear | 2.12 | 2.60 | ||
| 3 | Front | 2.16 | 2.64 | |
| Rear | 2.20 | 2.68 | ||
| 2014 | 1 | Front | 2.24 | 2.72 |
| Rear | 2.28 | 2.76 | ||
| 2 | Front | 2.32 | 2.80 | |
| Rear | 2.36 | 2.84 | ||
| 3 | Front | 2.40 | 2.88 | |
| Rear | 2.44 | 2.92 |
à la limite#
si je persiste, en faisant encore une fois stack(), j’obtiens cette fois .. une série
# ici stack part des colonnes vers les index
# donc les niveaux sont
# 0: name
# 1: tyre
# donc level=-1 désigne le niveau 'tyre'
stacked2 = pivot.stack().stack()
type(stacked2)
/tmp/ipykernel_1458/3133580498.py:7: FutureWarning: The previous implementation of stack is deprecated and will be removed in a future version of pandas. See the What's New notes for pandas 2.1.0 for details. Specify future_stack=True to adopt the new implementation and silence this warning.
stacked2 = pivot.stack().stack()
pandas.core.series.Series
et donc si vous avez suivi, le nombre de niveaux dans l’index de cette série, c’est ?
len(stacked2.index.levels)
4
produire le pivot à la main#
voyons maintenant comment on pourait produire le pivot sans passer par pivot_table(), et donc de manière plus pédestre, en gérant nous mêmes les index et les unstack()
c’est surtout pour le sport bien sûr, pour bien comprendre.
# on repart de la donnée brute
df.head()
| name | year | visit | tyre | pressure | |
|---|---|---|---|---|---|
| 0 | Bob | 2013 | 1 | Front | 2.00 |
| 1 | Bob | 2013 | 1 | Rear | 2.04 |
| 2 | Bob | 2013 | 2 | Front | 2.08 |
| 3 | Bob | 2013 | 2 | Rear | 2.12 |
| 4 | Bob | 2013 | 3 | Front | 2.16 |
la première chose à faire est donc de mettre les catégories en index
# et pour ça on peut faire par exemple
df_1column = df.set_index(['name', 'year', 'visit', 'tyre'])
df_1column.head()
| pressure | ||||
|---|---|---|---|---|
| name | year | visit | tyre | |
| Bob | 2013 | 1 | Front | 2.00 |
| Rear | 2.04 | |||
| 2 | Front | 2.08 | ||
| Rear | 2.12 | |||
| 3 | Front | 2.16 |
et là, il ne me reste plus qu’à faire quoi ?
je vous laisse réfléchir…
# ça marche pas trop mal, mais pas exactement
# car si je ne précise rien je vais avoir un arrangement
# qui dépend de l'ordre des niveaux dans l'index
# (unstack sans argument prend l'index=-1)
df_1column.unstack().unstack()
| pressure | |||||||
|---|---|---|---|---|---|---|---|
| tyre | Front | Rear | |||||
| visit | 1 | 2 | 3 | 1 | 2 | 3 | |
| name | year | ||||||
| Bob | 2013 | 2.00 | 2.08 | 2.16 | 2.04 | 2.12 | 2.20 |
| 2014 | 2.24 | 2.32 | 2.40 | 2.28 | 2.36 | 2.44 | |
| Sue | 2013 | 2.48 | 2.56 | 2.64 | 2.52 | 2.60 | 2.68 |
| 2014 | 2.72 | 2.80 | 2.88 | 2.76 | 2.84 | 2.92 | |
df_1column.unstack("name").unstack("tyre")
| pressure | |||||
|---|---|---|---|---|---|
| name | Bob | Sue | |||
| tyre | Front | Rear | Front | Rear | |
| year | visit | ||||
| 2013 | 1 | 2.00 | 2.04 | 2.48 | 2.52 |
| 2 | 2.08 | 2.12 | 2.56 | 2.60 | |
| 3 | 2.16 | 2.20 | 2.64 | 2.68 | |
| 2014 | 1 | 2.24 | 2.28 | 2.72 | 2.76 |
| 2 | 2.32 | 2.36 | 2.80 | 2.84 | |
| 3 | 2.40 | 2.44 | 2.88 | 2.92 | |
et groupby ?#
ici on a pris des données dans lesquelles il n’y a pas de répétition (par ex., on a une seule donnée pour Bob/2013/Front/1), on n’a donc pas eu besoin de faire de groupement ni d’agrégation.
dans le cas général, pivot_table sait aussi faire de l’agrégation
voyons, toujours pour le sport, comment on ferait à la main une pivot_table dans ce cas-là
et pour ça on va prendre notre éternal titanic
import seaborn as sns
titanic = sns.load_dataset('titanic')
titanic.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
objectif#
reproduire ceci sans utiliser pivot_table():
titanic.pivot_table(index='sex', columns='pclass', values='survived')
| pclass | 1 | 2 | 3 |
|---|---|---|---|
| sex | |||
| female | 0.968085 | 0.921053 | 0.500000 |
| male | 0.368852 | 0.157407 | 0.135447 |
groupby#
regardons pour commencer le résultat d’un groupby avec ces deux critères, et qui agrège avec mean pour faire la moyenne
grouped = titanic.groupby(by=['sex', 'pclass']).survived.mean()
grouped
sex pclass
female 1 0.968085
2 0.921053
3 0.500000
male 1 0.368852
2 0.157407
3 0.135447
Name: survived, dtype: float64
on obtient donc une série parce que
avec
.groupbyon obtient une collection de dataframesen faisant
.survivedon s’est ramené à une collection de sériesen faisans
.mean()on s’est ramené à une collection de nombres (les moyennes)
et surtout ce qui nous intéresse ici c’est que l’index de cette série est de profondeur 2 (parce qu’on a donné 2 critères au groupby)
grouped.index
MultiIndex([('female', 1),
('female', 2),
('female', 3),
( 'male', 1),
( 'male', 2),
( 'male', 3)],
names=['sex', 'pclass'])
pivot_table = groupby + unstack#
et donc on peut tout simplement reproduire le premier pivot_table() en faisant
pivot2 = titanic.groupby(by=['sex', 'pclass']).survived.mean().unstack()
pivot2
| pclass | 1 | 2 | 3 |
|---|---|---|---|
| sex | |||
| female | 0.968085 | 0.921053 | 0.500000 |
| male | 0.368852 | 0.157407 | 0.135447 |
bon c’est beaucoup plus court et lisible avec pivot_table(), mais vous pouvez constater que c’est vraiment une fonction de confort uniquement, qui se refait assez facilement par d’autres moyens